트래픽이 몰려다니면서 서버를 폭파시킨다
AWS Beanstalk 환경에서 스파이크 트래픽으로 인해 인스턴스 간 트래픽이 몰려다니는 현상의 원인과 Slow Start, 드레이닝, 헬스체크 최적화 등 대처 방법을 정리합니다.

트래픽이 몰려다니면서 서버를 폭파시킨다
AWS Beanstalk을 사용해서 어플리케이션 서버를 생성하면, 로드밸런서와 대상그룹등이 자동으로 생성된다. 빈스톡의 장점이라면 장점이지만, 이 ‘자동’이라는 함정으로 인해서 로드밸런서와 대상그룹에 있는 상세 설정들을 눈여겨 보지 않게 되는 것 같다.
스파이크 트래픽(spike traffic)으로 인해서 트래픽이 몰려다니게 되는 현상
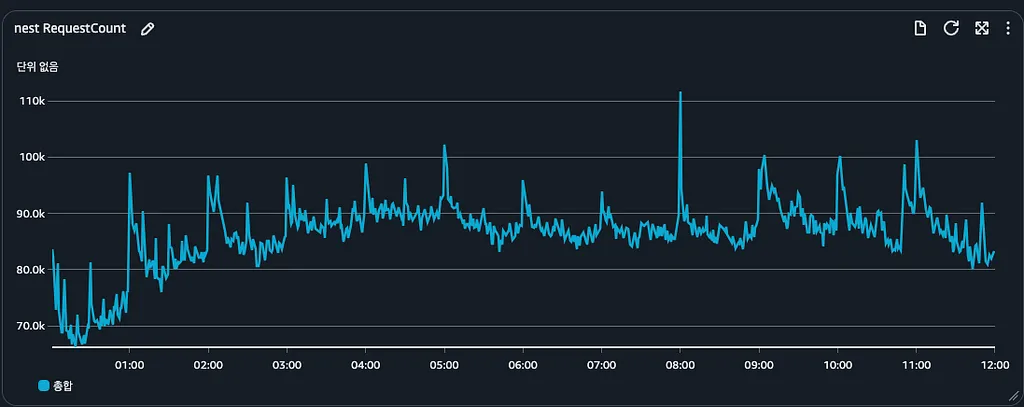
중간중간 뾰족한 트래픽처럼 일정 기간 많은 요청이 들어오게 되는 경우에 다음과 같은 시나리오가 발생할 수 있다.
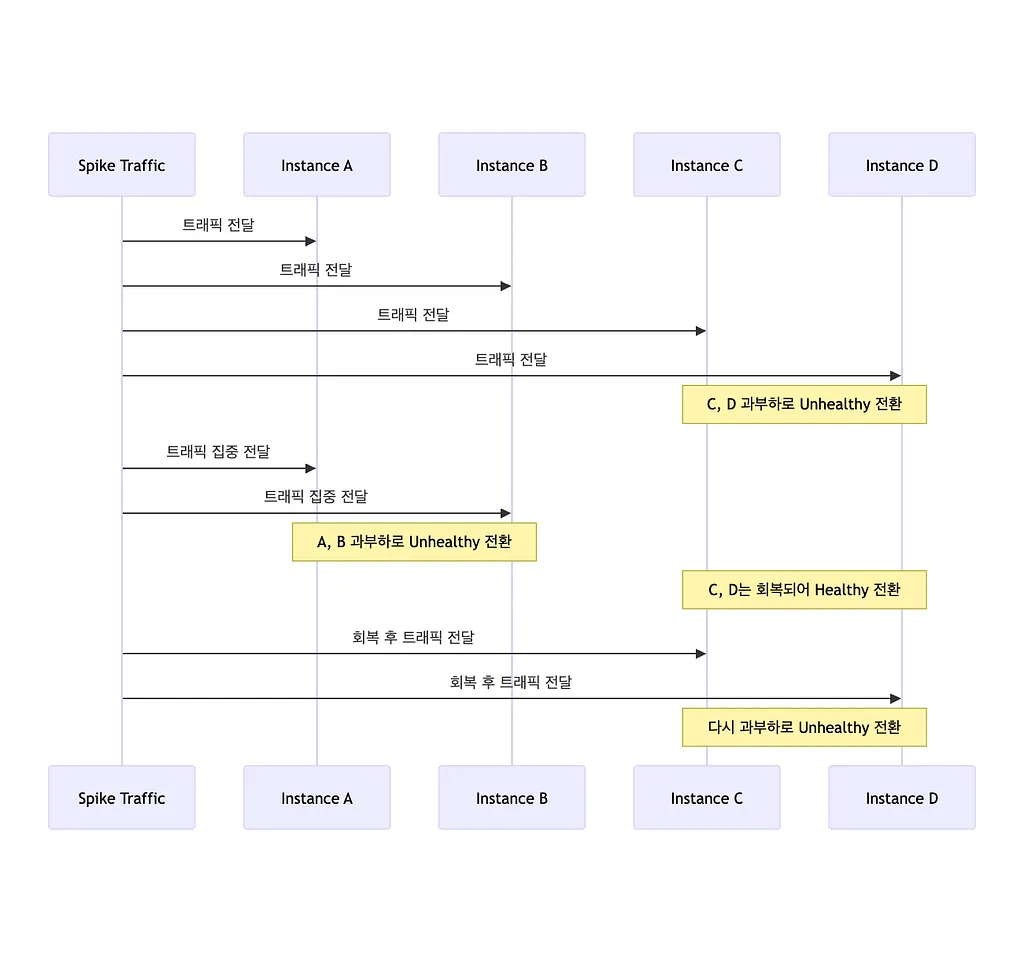
- 인스턴스 네개(A, B, C, D)가 Spike 트래픽을 수신한다.
- 그 중 일부(C, D)가 더 이상 트래픽을 받을 수 없는 상태가 되어, unhealthy 로 바뀐다.
- 이후 모든 트래픽은 정상(healthy)상태인 A, B인스턴스에 몰린다.
- A, B인스턴스는 둘이서 모든 트래픽을 받아야 하기 때문에 과부하로 인해 unhealthy상태로 바뀐다.
- C, D 인스턴스가 잠시 트래픽을 받지 않는 동안 정상 상태로 돌아왔고, healthy 상태가 된다.
- 모든 트래픽은 다시 C, D인스턴스로 몰리게 되고 C, D인스턴스는 다시 unhealthy로 바뀐다.
이 시나리오에서 가장 큰 문제점은 ‘빈스톡이 제공하는 오토 스케일링’만으로는 서버 스스로 대처가 안된다는 점이다.
위 시나리오에서 빈스톡 오토스케일링이 적용되었다고 가정해보자. 우선 평균 CPU 사용량 지표를 기준으로 오토스케일링이 적용되었다고 가정한다.
- 우선 위 시나리오에서 트래픽은 ‘절반의 인스턴스’만 수신한다. 때문에 절반의 인스턴스는 CPU 사용량이 100%가 되고, 나머지 절반 인스턴스는 트래픽을 아예 받지 않기 때문에 Idle CPU만 사용한다 (20%라고 가정해보자)
- 그렇다면, 평균 CPU지표는 (100 + 100 + 20 + 20 ) / 4 = 60(%) 가 된다. 즉, 빈스톡은 평균에 속아서 서버 평균 CPU에는 문제가 없다고 표시한다. 그래서 인스턴스를 증설하지 않는다.
- 만약 인스턴스 증설 기준을 낮게 (평균 CPU 40%) 해놓았다고 가정해보자. 그러면 인스턴스는 설정해놓은 수 만큼 증설을 시작한다. 예를 들어 1대씩 증설한다고 해보자. (전체 인스턴스의 1/4 이기 때문에 25% 정도를 증설한다는 가정이다.)
- 위 시나리오에서 1대가 증설을 성공했다고 해도, 총 5대(기존 4 + 신규 1) 중 unhealthy 2대를 제외하면 healthy 인스턴스는 3대뿐이다. 원래 4대가 모두 분산해도 버거운 트래픽을 3대가 받아야 하기 때문에 unhealthy 상태에서 벗어나지 못하게 된다.
이러한 문제들로 Beanstalk이 자동으로 설정해주는 오토스케일링, 로드밸런서, 대상그룹 설정을 맹신하면 안된다.
위 시나리오를 어떻게 대처할 수 있을까 찾게 된 몇가지 옵션을 소개한다. 이 옵션들이 위 시나리오를 완벽히 막을 수 있을 것 같지는 않다. 다만 빈도를 줄일 수는 있을 것 같다.
1. Slow Start 모드 활성화
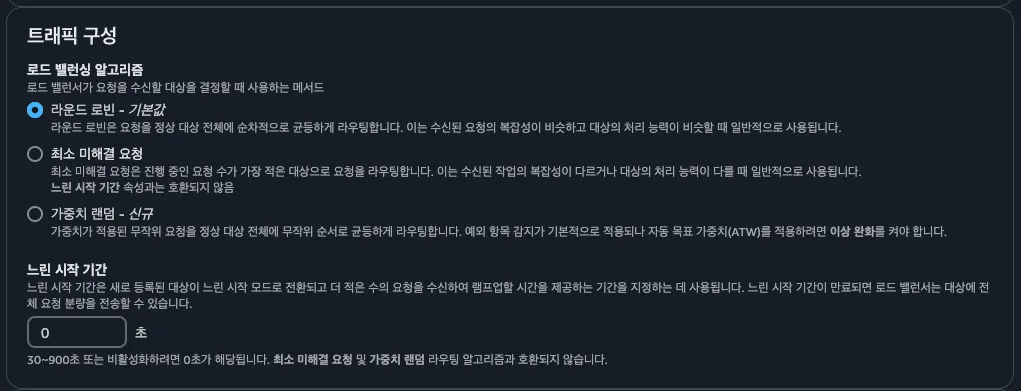
대상그룹 옵션 중에 느린 시작 기간이라는 기능이다.
기본적으로 대상은 대상 그룹에 등록되고 초기 상태 검사를 통과하자마자 전체 공유 요청을 수신하기 시작한다. 느린 시작 모드를 사용하면 로드 밸런서가 전체 공유 요청을 보내기 전에 대상이 워밍업할 시간이 주어진다.
대상 그룹에 대해 슬로우 스타트를 활성화한 후, 대상 그룹에서 정상으로 간주되면 대상은 슬로우 스타트 모드로 전환된다. 슬로우 스타트 모드의 대상은 구성된 슬로우 스타트 기간이 경과하거나 대상이 비정상이 되면 슬로우 스타트 모드를 종료한다.
로드 밸런서는 슬로우 스타트 모드의 대상에 보낼 수 있는 요청 수를 선형적으로 증가시킨다.
2. 대상 등록취소 지연 시간 수정 (드레이닝 간격)

인스턴스가 대상 그룹에서 제거될 때, 일정 시간 동안 기존 연결을 유지하여 정상적인 연결 종료를 보장하는 설정이다.
과부하 인스턴스가 제거될 때 급격한 트래픽 전환을 완화하여, 갑자기 다른 인스턴스에 몰리는 현상을 줄일 수 있다.
대상 그룹 설정에서 Deregistration Delay를 상황에 맞게 늘려서 적용할 수 있다.
3. 대상 그룹 상태 요구 사항
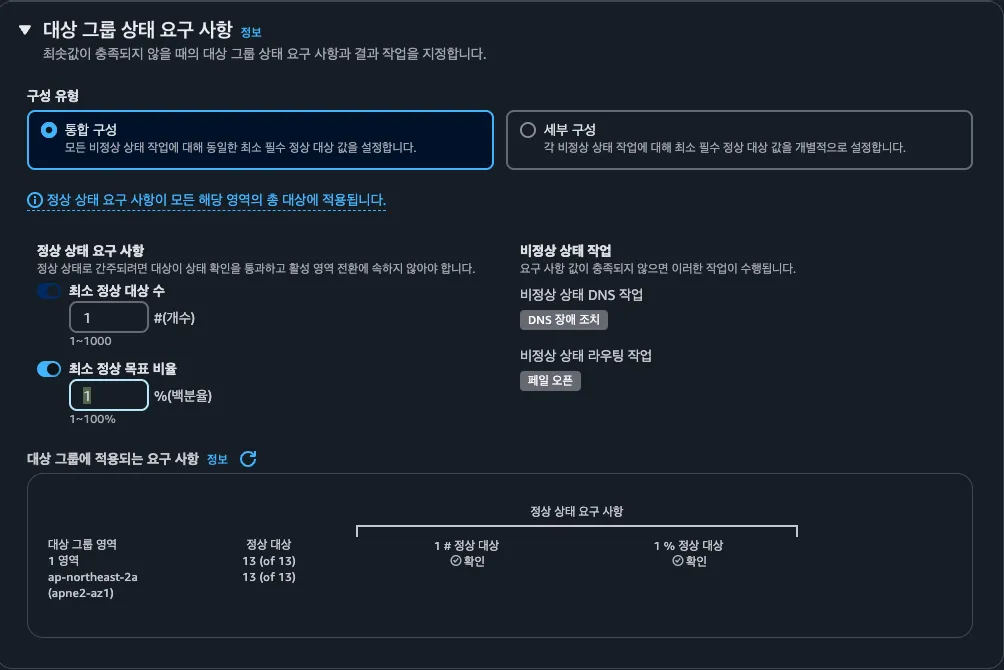
최소 정상 대상 수, 최소 정상 목표 비율을 지정하여 이 조건에 합하지 않은 경우에는 DNS장애조치, 비정상 상태 라우팅 (페일 오픈)을 진행하도록 할 수 있다.
비정상 상태 라우팅(Fail Open)은 최소 정상 비율 조건에 미달했을 때, unhealthy 인스턴스를 포함한 모든 인스턴스에 트래픽을 분산시키는 방식이다. 즉, 503을 일괄 응답하는 것이 아니라 “비정상 인스턴스라도 시도해보자”는 전략이다.
위 시나리오가 계속된다면, 시나리오가 종료될 때까지 계속해서 트래픽중 절반 정도만 정상 요청/응답이 진행되게 된다. 그렇지만 위 옵션을 사용해서 최소 정상 목표 비율을 80% 정도로 해둔다면, 정상 인스턴스가 80% 미만일 때 unhealthy 인스턴스에도 트래픽을 보내게 된다. 이렇게 하면 특정 인스턴스에만 트래픽이 몰리는 핑퐁 현상을 완화하고, 부하를 전체 인스턴스에 고르게 분산시킬 수 있다.
4. 헬스체크 설정 최적화

헬스체크 민감도가 높으면 인스턴스가 일시적으로 과부하 상태에 빠졌을 때 쉽게 unhealthy로 전환된다.
헬스체크의 임계치나 간격을 조정하여, 과도한 unhealthy 전환을 막고 인스턴스가 잠깐의 부하 상승을 견디도록 할 수 있다.
헬스체크 경로, 간격, 실패 허용 횟수 등을 상황에 맞게 재설정하여, 인스턴스의 상태 전환을 보다 안정적으로 관리할 수 있다.



