원인불명 CPU사용량 급증에 대처했던 방법 (1)
Beanstalk 인스턴스에서 원인불명의 CPU 사용량 급증 문제를 perf와 strace로 분석하여 Datadog 프로파일링 시그널이 원인임을 밝혀낸 과정을 기록합니다.

원인불명 CPU사용량 급증에 대처했던 방법 (1)
CPU 분석 삽질 일기
문제상황
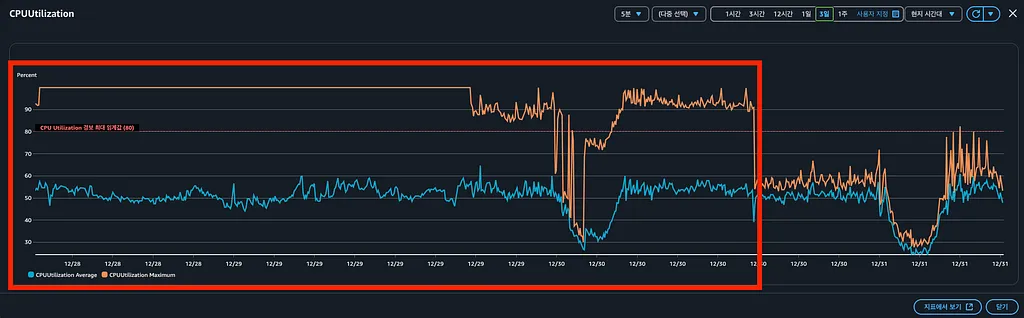
어느날 부터 빈스톡에 떠 있는 인스턴스 중 일부 인스턴스에서 CPU 경보가 보이기 시작했습니다. 대부분의 인스턴스는 지표가 정상이었기 때문에, 당장 사용자에게 문제가 생길만한 크리티컬한 이슈는 아니었습니다.
이 문제에는 특이한 특징이 있었습니다.
- 몇몇 인스턴스만 CPU 사용량이 100%로 급증했다. 20개의 인스턴스가 실행되고 있을 때, 2~3개 인스턴스에서 발생, 시간이 지날수록 더 많은 인스턴스에서 발생하는 특징이 있었습니다.
- CPU 사용량 100%를 기록하고 다시 돌아오지 않았다. 보통 어떤 작업이 CPU를 과하게 사용하게 되면, 해당 작업이 끝난 이후에는 CPU가 다시 정상 수치로 돌아와야 하지만, 이 경우에는 100%를 기록한 이후에는 다시 정상 수치로 돌아오지 않는 특징이 있었습니다.
- 사용자 CPU가 아닌, 시스템 CPU가 급증했다. 노드 프로세스가 문제였다면, CPU 사용자 지표가 증가하게 된다. 그런데 이번에는 CPU 시스템 점유율이 40%가 넘게 올라갔다
접근
알고 있는 정보를 토대로, 문제를 해결하기 위해 여러 시도들을 했습니다. 어떤 배포 이후부터 문제가 있었는지, 또 어떤 요청 이후에 CPU가 급증하는지 확인하고, 새로운 환경을 만들어서 실험해보기도 했습니다. 또, 프로세스가 무한 루프에 들어가지는 않았는가? 라는 질문이 있었고 실제로 while(true) 혹은 재귀로 동작하는 몇몇 반복문들이 서비스 로직에 있었습니다. while문을 제거하고, 여러 모니터링툴을 이용해서 문제를 파악하고 고쳐보려고 했지만 문제가 해결되지 않았습니다. 명확한 타겟을 모른 채로 난사를 하다가, 이 문제를 조금 더 깊이 파볼 수 있는 시간이 생겨서 처음부터 제대로 접근해보기로 했습니다.
1. 누가 CPU를 사용하고 있는가?
당시 CPU 사용률을 보면, node 프로세스 두개가 압도적으로 많은 CPU를 사용하고 있고, 특이하게 system CPU가 37프로 이상 사용되고 있었습니다.
top - 02:22:21 up 4:50, 2 users, load average: 2.95, 2.78, 2.70
Tasks: 155 total, 3 running, 152 sleeping, 0 stopped, 0 zombie
%Cpu(s): 58.4 us, 37.1 sy, 0.0 ni, 3.5 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
MiB Mem : 3812.1 total, 175.9 free, 1550.3 used, 2086.0 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 2039.1 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2872 webapp 20 0 9971.6m 507080 57992 R 102.3 13.0 231:24.50 node-20
2873 webapp 20 0 9931.8m 440036 58036 R 87.4 11.3 222:09.69 node-20
2793 nginx 20 0 17496 5632 2448 S 1.0 0.1 1:47.90 nginx
2607 dd-agent 20 0 2452380 204428 110636 S 0.7 5.2 1:30.97 agent
2609 dd-agent 20 0 1908012 104440 48276 S 0.7 2.7 2:58.08 trace-agent
2792 nginx 20 0 17652 5616 2448 S 0.7 0.1 1:47.55 nginx이 정보로는, 도대체 무엇 때문에 CPU가 증가했는지 알기가 어려웠습니다. 문제가 발생하기 시작했던 시점 근처에 배포되었던 코드 중에 외부 API를 호출하는 코드가 있었습니다. 제가 의도하지 않게 네트워크 소켓이 빈번하게 열리고 닫히는가 먼저 확인했습니다. 아래 결과는 ss -s 커맨드를 3초 간격으로 실행했던 결과입니다.
[root@ip-172-31-0-84 log]# ss -s
Total: 349
TCP: 206 (estab 146, closed 48, orphaned 0, timewait 37)
Transport Total IP IPv6
RAW 1 0 1
UDP 9 7 2
TCP 158 115 43
INET 168 122 46
FRAG 0 0 0[root@ip-172-31-0-84 log]# ss -s
Total: 354
TCP: 209 (estab 149, closed 48, orphaned 0, timewait 37)
Transport Total IP IPv6
RAW 1 0 1
UDP 9 7 2
TCP 161 118 43
INET 171 125 46
FRAG 0 0 0[root@ip-172-31-0-84 log]# ss -s
Total: 357
TCP: 211 (estab 152, closed 47, orphaned 0, timewait 36)
Transport Total IP IPv6
RAW 1 0 1
UDP 9 7 2
TCP 164 121 43
INET 174 128 46
FRAG 0 0 0[root@ip-172-31-0-84 log]# ss -s
Total: 356
TCP: 212 (estab 153, closed 47, orphaned 0, timewait 36)
Transport Total IP IPv6
RAW 1 0 1
UDP 9 7 2
TCP 165 122 43
INET 175 129 46
FRAG 0 0 0네트워크 지표에는 큰 특이사항이 없었고, netstat으로 확인했을 때에도 소켓이 과하게 많이 생성됐다던가 하는 특이 지표는 보이지 않았습니다.
2. CPU는 지금 어떤 일을 하고 있는가?
예상 원인을 리스트업하고 하나씩 확인하는 방식도 뾰족한 방법이 아니라고 생각이 들었고, CPU가 어떤 명령을 처리하고 있는지 확인하는 방법을 선택했습니다. 지금 와서 생각해보면, 가장 최초에 이 방식을 선택해야 했습니다.
CPU가 사용하고 있는 함수의 비율을 조회해보자
데이터독 프로파일러에서는 유의미한 지표를 찾아보기 어려웠고, 인스턴스에서 직접 CPU를 프로파일링할 수 있는 툴을 먼저 설치했습니다.
sudo yum install perf이후 perf를 사용해서 어떤 함수들이 CPU를 호출하고 있는가 요약할 수 있었습니다.
sudo perf record
sudo perf report- 비정상 인스턴스의 결과
Samples: 522K of event 'cycles', Event count (approx.): 297761191712
Overhead Command Shared Object Symbo
6.01% node-20 [kernel.kallsyms] [k] e
2.04% node-20 [kernel.kallsyms] [k] s
1.90% node-20 [kernel.kallsyms] [k] f
1.69% node-20 libnode.so.115 [.] v
1.54% node-20 [kernel.kallsyms] [k] e
1.40% node-20 [kernel.kallsyms] [k] r
1.40% node-20 [kernel.kallsyms] [k] a
...- 정상 인스턴스의 결과
Samples: 364K of event 'cycles', Event count (approx.): 191623436563
Overhead Command Shared Object Symbo
2.20% node-20 libnode.so.115 [.] v
2.04% tokio-runtime-w libc.so.6 [.] _
1.30% tokio-runtime-w libc.so.6 [.] m
1.23% tokio-runtime-w libc.so.6 [.] _
0.98% node-20 libnode.so.115 [.] v
...결과 : 비정상적으로 많은 kernel.kallsyms 함수가 호출되고 있다.
Overhead Command Shared Object Symbol
6.01% node-20 [kernel.kallsyms] [k] el0_svc_common.constprop.0
2.04% node-20 [kernel.kallsyms] [k] setup_sigframe
1.90% node-20 [kernel.kallsyms] [k] force_sig_info_to_task
1.69% node-20 libnode.so.115 [.] v...
1.54% node-20 [kernel.kallsyms] [k] el0_da
...
0.62% node-20 [kernel.kallsyms] [k] page_remove_rmap
...정상 인스턴스에서는 node프로세스에서 실행되는 libnode.so.115 관련 호출이 지배적이지만, 비정상 인스턴스에서는 어째서인지 kernel.kallsyms가 많이 호출되고 있었습니다.
당시 perf 결과를 가져오는 과정에서 symbol 데이터가 짤렸는데, 위에처럼 el0_svc_common.constprop.0, setup_sigframe, force_sig_info_to_task 세가지 심볼이 가장 많이 차지하는 것을 확인했습니다.
GPT를 통해서 위 세가지 심볼에 대해 확인했고, GPT는 이 세가지 심볼이 자주 등장하는 패턴이 datadog과 profiler가 보내고 있는 시그널이 문제일 수 있다는 의견을 제시했습니다.
이 때부터, datadog을 의심하기 시작했고, 더 확실한 증거를 찾기 위해서 strace를 활용하게 됐습니다.
CPU에서 발생하고 있는 모든 signal과 system call을 조사해보자
perf 명령으로는 확인할 수 있는 정보가 제한적이어서 대안을 찾게 되었고, 그 중 하나가 strace였습니다. strace를 이용해서, 해당 프로세스에서 발생하고 있는 시스템 콜을 확인했습니다.
strace -c -p <PID>- 비정상 인스턴스 결과
[root@ip-172-31-0-84 log]# strace -c -p 2852
strace: Process 2852 attached
^Cstrace: Process 2852 detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
46.78 2.026571 1 1266953 633476 write
29.00 1.256125 1 636891 rt_sigreturn
24.23 1.049480 1 633477 read
------ ----------- ----------- --------- --------- ----------------
100.00 4.332176 1 2537321 633476 total- 정상 인스턴스 결과
[root@ip-172-31-13-94 ec2-user]# strace -c -p 67254
strace: Process 67254 attached
^Cstrace: Process 67254 detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
64.56 0.093446 12 7354 2009 epoll_pwait
12.46 0.018039 5 3264 121 futex
9.85 0.014261 4 3076 write
4.20 0.006076 12 480 7 writev
3.36 0.004870 1 2918 2010 rt_sigreturn
2.60 0.003761 1 3733 read
...결과 : write, read, rt_sigreturn 이 CPU 타임의 모든 비율을 차지하고 있다.
정상 인스턴스에서는 epoll_pwait (nodejs 이벤트 루프에서 활용하는 시스템 콜), futex, write, read 등이 골고루 분포되어있지만, 비정상 인스턴스에서는 write, read, rt_sigreturn가 대부분을 차지하고 있다는 특이점이 있었습니다.
노드 프로세스가 데이터독의 프로파일링 시그널을 받아서, 해당 시그널의 결과를 반환하는데에 write, read를 모두 사용하고 있는 것인가?
라는 의문이 들었고, 노드 프로세스가 받고 있는 시그널이 데이터독으로부터 온 프로파일링 시그널인지 확실히 확인하고 싶어졌습니다.
프로세스가 수신하고 있는 모든 시그널을 확인해보자
아래 명령어를 통해서 해당 프로세스가 수신하고 있는 모든 시그널과, 수행중인 시스템 콜을 확인할 수 있었습니다.
strace -f -p <PID> -e signal=all- 비정상 인스턴스
[pid 2911] getpid() = 2853
[pid 2911] tgkill(2853, 2853, SIGPROF) = 0
[pid 2911] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 2911] futex(0xaaab06036c88, FUTEX_WAKE_PRIVATE, 1) = 0
[pid 2911] futex(0xaaab06036c80, FUTEX_WAIT_BITSET_PRIVATE, 0, {tv_sec=30769, tv_nsec=191233000}, FUTEX_BITSET_MATCH_ANY <unfinished ...>
[pid 2886] write(23, "\1\0\0\0\0\0\0\0", 8 <unfinished ...>
[pid 2853] --- SIGPROF {si_signo=SIGPROF, si_code=SI_TKILL, si_pid=2853, si_uid=900} ---
...- 정상 인스턴스
[pid 67285] getpid() = 67254
[pid 67285] tgkill(67254, 67254, SIGPROF) = 0
[pid 67254] <... epoll_pwait resumed>0xffffdbcaa538, 1024, 41, NULL, 8) = -1 EINTR (Interrupted system call)
[pid 67285] rt_sigprocmask(SIG_SETMASK, [], <unfinished ...>
[pid 67254] --- SIGPROF {si_signo=SIGPROF, si_code=SI_TKILL, si_pid=67254, si_uid=900} ---
...각 인스턴스의 기록중에서 getpid() 호출을 반복의 시작점으로 잡았습니다. 앞 뒤로는 거의 비슷한 패턴이 반복되고 있습니다.
우선 이 결과에서 SIGPROF 시그널을 확인하자마자 직관으로 ‘아! datadog 맞구나’생각이 들었습니다. 다만 조금 더 근거를 갖기 위해서, 한줄한줄 확인해봤습니다.
여기서 부터는 GPT의 힘을 강력하게 빌렸습니다
1. getpid() + tgkill(… , …, SIGPROF)
getpid(): 현재 프로세스(스레드) PID를 가져옵니다.tgkill(2853, 2853, SIGPROF): Linux에서 특정 스레드 그룹(tg) 내 스레드에게 시그널을 보내는 시스템콜입니다. 여기서 2853은 node프로세스 입니다. node 프로세스에 SIGPROF 시그널을 전달하게 됩니다.
2. rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
- 시그널 마스크(SIG_SETMASK)를 제거하는 명령입니다.
- 노드 프로세스가 SIGPROF시그널을 시그널 마스크를 통해 막고 있을 수 있으니, 시그널 마스크를 비워주는 것 같습니다.
3. futex(…) (WAKE, WAIT_BITSET, ETIMEDOUT)
futex는 스레드간 동기화를 위해 사용합니다.- 프로세스 2911이 해당 메모리 주소를 바라보고 있는 다른 스레드를 깨우기 위해 호출했습니다.
- 최대 30,769초 동안 대기하도록 설정되었습니다. 이 호출은 아직 완료되지 않았습니다.
4. SIGPROF + rt_sigreturn
- SIGPROF가 실제로 해당 프로세스(스레드)에 도착했다는 표시입니다.
- 시그널 핸들러가 실행된 뒤, rt_sigreturn을 통해 시그널 처리 루틴에서 복귀합니다.
- 즉, 1. Datadog(또는 내부 프로파일러) -> SIGPROF 보냄, 2. Node.js(스레드 2853) -> 시그널 핸들러 돌아감 -> CPU 점유 + 처리 -> rt_sigreturn
5. write(…)
- 커널에 write() 호출. 여기서는 fd=23인 어떤 소켓 혹은 파이프 같은 곳에 8바이트를 쓰고 있습니다.
6. epoll_pwait(…)
- 프로세스 2886이 epoll_pwait() 호출을 통해 파일 디스크립터에서 읽기(EPOLLIN)와 쓰기(EPOLLOUT) 이벤트를 감지했습니다.
- epoll_pwait()는 Node.js(libuv)가 비동기 I/O를 처리할 때 사용.
7. futex(…) 반복 패턴
- Node.js에서 스레드들이 대기 -> 시그널 도착 -> 한쪽 스레드가 깨어남 -> 다시 WAIT … 하는 패턴이 빈번하게 관찰.
- nodejs에서 어떤 작업 수행을 위해서 WAIT -> WAKE -> EAGAIN로 스레드끼리 동기화를 하는 동안 SIGPROF가 짧은 간격으로 끼어들기 시작하면, 컨텍스트 스위칭으로 CPU를 많이 소모합니다.
왜 CPU가 많이 소모되는가?
- Datadog이 SIGPROF를 일정 시간마다 보내는데, 시그널 처리가 너무 빈번하게 일어나면서 context switch 비용이 발생
- CPU가 증가하면서 때로는 시그널 처리가 끝나기도 전에 다시 시그널이 와서 중첩(혹은 연쇄)되는 상황.
- 즉, 시그널 처리 루틴이 빈번하게 실행되면서 Nodejs가 수행하고 있던 futex/epoll 같은 동기화, I/O 대기를 중지시킴 Node.js의 의도대로 되지 못하고 중단됐다가 profiling signal을 우선 처리하고 다시 돌아옴 -> context switch 폭발, CPU 소모 증가.
왜 특정 인스턴스에서만 발생했는가?
- Datadog의 프로파일링 signal과 Node.js의 워커 스레드/이벤트 루프 상태가 우연히 맞물리면서 SIGPROF 시그널이 점점 누적되는 현상이 발생한 것으로 보입니다.
해결
- Datadog Profiling(DD_PROFILING_ENABLED) 환경 변수 false로 수정했습니다.
- 이후 CPU max 지표가 정상적으로 돌아왔습니다.
회고
- 문제가 해결되고 나서 생각해보면, 하루 정도만 시간을 내서 인스턴스를 조금 더 꼼꼼히 조사했다면 다른 시도를 하지 않고도 문제를 해결할 수 있었을 것 같습니다.
- 이 하루를 사용하지 않아서, 다른 작업을 난사(정확한 근거와 목표물 없이 일단 시도해보기)했던 것이 아쉬운 것 같습니다.
- 해보지 않은 작업에 대한 막연한 두려움도 작용했던 것 같습니다
- 인스턴스에서 직접 CPU 분석 -> 해보지 않은 작업 -> 괜히 어려울 것 같고 하기 싫다.
- 반복문 제거, datadog trace 분석 -> 늘 해봤던 간단한 작업 -> 일단 해보기 편하다.



