원인 불명 CPU사용량 급증에 대처했던 방법 (3)
1년 전 끝까지 파보지 못했던 CPU 급증 문제를 AI와 함께 다시 분석해봤습니다. 당시 남겨뒀던 의문들에 대해 더 깊은 답을 찾아가는 회고입니다.

원인 불명 CPU사용량 급증에 대처했던 방법 (3)
1년이 지난 지금, AI와 함께 다시 돌아보다
왜 다시 돌아보게 되었는가
이전 두 편의 글 (원인 불명 CPU사용량 급증에 대처했던 방법 1편, 2편)에서, Datadog 프로파일링이 원인이라는 것까지는 찾아냈지만 “정확히 왜?”에 대한 답은 결국 내지 못하고 글을 마무리했었다.
2편의 마지막에 이렇게 적었었다.
더 깊게 파보기에는, 시간을 쏟는 공수 대비 효과가 적다고 판단했습니다.
맞는 판단이었다. 이미 해결 방법(프로파일링 끄기)은 나와있는 상태였고, 다른 업무에 집중하는 것이 옳았다. 그런데 그 이후로도 가끔씩 머릿속에서 이 문제가 떠올랐다. “그래서 진짜 원인이 뭐였는데?”라는 질문이 해소되지 않은 채로 남아있었기 때문이다.
최근 블로그를 정리하면서 예전 글들을 다시 읽게 되었고, 이번에는 AI(Claude)에게 당시 수집했던 증거들을 전부 보여주고 분석을 요청해봤다. 혼자서는 놓쳤던 부분들이 꽤 보여서, 그 내용을 기록으로 남기려 한다.
CASE 1 다시 보기: SIGPROF 무한 반복
미해결 의문 1: 왜 일부 인스턴스에서만 발생했는가?
당시 글에서 이렇게 적었었다.
Datadog의 프로파일링 signal과 Node.js의 워커 스레드/이벤트 루프 상태가 우연히 맞물리면서 SIGPROF 시그널이 점점 누적되는 현상이 발생한 것으로 보입니다.
솔직히 이건 “잘 모르겠다”를 점잖게 적은 것에 가까웠다.
AI에게 당시 strace 결과를 보여줬더니, 이런 포인트를 짚어줬다.
strace에서 프로파일러 스레드(pid 2911)가
tgkill()로 직접 SIGPROF를 보내고 있습니다. 이건 커널의setitimer()가 주기적으로 보내는 것이 아니라, ddprof의 스레드가 명시적으로 시그널을 발사하고 있다는 뜻입니다.
이 지적을 보고 다시 strace 결과를 살펴봤다.
[pid 2911] getpid() = 2853
[pid 2911] tgkill(2853, 2853, SIGPROF) = 0맞다. pid 2911(v8:ProfEv 스레드)이 getpid()로 PID를 가져온 뒤, tgkill()로 직접 SIGPROF를 쏘고 있다. 커널 타이머가 보내는 게 아니라, ddprof가 자체적으로 시그널을 보내고 있었던 것이다. 그렇다면, 이 스레드의 루프에 rate limiting 버그가 있거나, 특정 조건에서 throttle 없이 tight loop에 빠질 수 있다는 뜻이 된다.
그리고 이건 “왜 일부 인스턴스에서만 발생했는가?”에 대한 설명이 된다. 프로파일러 스레드가 tight loop에 진입하는 조건이 race condition이라면, 확률적으로 일부 인스턴스에서만 걸려드는 것이 자연스럽다. V8 GC 타이밍, JIT 컴파일 상태, 특정 메모리 레이아웃 등이 맞물려야 발생하는 것이다.
시간이 지날수록 더 많은 인스턴스에서 발생했던 것도 설명이 된다. 각 인스턴스가 단위 시간당 일정 확률로 이 조건에 걸려드니까, 시간이 지나면 자연스럽게 걸려드는 인스턴스가 늘어나는 것이다.
미해결 의문 2: 왜 한번 올라가면 절대 돌아오지 않는가?
이것도 당시에는 명확하게 설명하지 못했었다. AI의 분석은 단순했다.
프로파일러 스레드가 한번 tight loop에 진입하면, “내가 CPU를 과도하게 쓰고 있으니 멈춰야겠다”는 자기 교정 로직이 없기 때문입니다. 외부에서 프로세스를 죽이거나 설정을 바꾸지 않는 한, 스스로 안정 상태로 돌아올 수 없는 구조입니다.
피드백 루프가 한쪽 방향으로만 동작한다는 것이다. 프로파일러가 SIGPROF를 쏘고 → 핸들링에 CPU를 쓰고 → 프로파일러 스레드는 상관없이 계속 쏘고 → CPU가 더 올라가고. 여기서 “CPU가 너무 높으니 시그널 빈도를 줄이자”는 피드백이 없다. 당연한 것 같으면서도, 명확하게 정리하고 나니 속이 시원해지는 느낌이다.
CASE 2 다시 보기: SIGSEGV 무한 반복
AI에게 당시 strace 결과를 보여주고 분석을 요청했다. 그런데 AI가 가장 먼저 짚어준 것은 내 가설의 근본적인 문제였다.
당시 나의 가설은 틀렸다
2편에서 이렇게 추측했었다.
핸들러에서 버퍼를 다루거나, backtrace, backtrace_symbols_fd 함수를 실행하는 도중에 SIGSEGV시그널이 다시 발생 됨
즉, ddprof의 시그널 핸들러 안에서 또 SIGSEGV가 터져서 재귀적으로 무한 반복된다는 가설이었다.
그런데 이 가설에는 근본적인 문제가 있었다. ddprof는 Node.js 프로세스 안에서 실행되는 라이브러리가 아니라, 완전히 별도의 프로세스로 동작하는 네이티브 프로파일러다. perf_event_open과 ptrace를 사용해서 외부에서 대상 프로세스를 프로파일링하는 구조다.
서로 다른 프로세스의 시그널 핸들러는 완전히 독립적으로 동작한다. 즉, ddprof의 sigsegv_handler는 ddprof 자체의 크래시를 보호하기 위한 것이지, Node.js 프로세스의 SIGSEGV와는 아무 관련이 없다. 내가 2편에서 ddprof 코드를 분석하고 async-safe 문제를 찾아서 PR까지 올렸지만, 그것은 ddprof 코드의 품질 개선이었을 뿐, 우리가 관찰한 Node.js의 SIGSEGV 무한 반복과는 직접적인 관련이 없었던 것이다.
그러면 실제로 SIGSEGV를 처리하고 있는 것은 무엇인가?
ddprof의 핸들러와 무관하다면, Node.js 프로세스 안에서 SIGSEGV를 처리하고 있는 것은 무엇인가?
AI는 strace에 찍힌 read(7) → write(22) → write(8) → rt_sigreturn 패턴이 self-pipe trick이라고 했다.
read(7)→write(22)→write(8)→rt_sigreturn패턴은, Node.js(libuv)가 시그널을 비동기적으로 처리하기 위해 사용하는 self-pipe trick의 전형적인 패턴입니다. 시그널이 오면 파이프에 1바이트를 써서 이벤트 루프에 알리고, 나중에 이벤트 루프가 처리하는 방식입니다.
결국 SIGSEGV를 처리하고 있는 것은 Node.js(libuv) 쪽의 시그널 핸들러이고, 이 핸들러는 프로세스를 종료시키지 않고 rt_sigreturn으로 정상 복귀한다.
그러면 왜 무한 루프인가?
이 부분이 핵심이다. AI의 설명을 듣고 ‘아..’ 했던 부분이다.
시그널 핸들러가
rt_sigreturn으로 정상 복귀하면, CPU는 시그널이 발생했던 바로 그 명령어(faulting instruction)를 다시 실행합니다. 원인(NULL 포인터)이 해결되지 않았으니, 같은 명령어가 다시 SIGSEGV를 발생시키고, 핸들러가 다시 호출되고, 다시 복귀하고, 다시 같은 명령어를 실행하고… 영원히 반복됩니다.
내 가설은 “핸들러 안에서 SIGSEGV가 재발생한다”였는데, 실제로는 더 단순했다. 핸들러는 정상적으로 끝나지만, 복귀한 지점의 코드가 여전히 잘못된 메모리를 참조하고 있어서 바로 다시 SIGSEGV가 터지는 것이다.
일반적으로 SIGSEGV의 기본 동작(SIG_DFL)은 프로세스를 종료시키는 것이다. 하지만 Node.js 프로세스 내부의 시그널 핸들러가 SIGSEGV를 가로채서 종료 대신 rt_sigreturn으로 복귀하면서, 프로세스가 죽지도 않고 복구도 안 되는 최악의 상태에 빠진 것이다.
si_addr=0xe3a8의 의미
AI가 SIGSEGV의 fault address에 대해서도 분석을 해줬다.
si_addr=0xe3a8은 약 58KB 정도의 매우 낮은 주소입니다. 이건 전형적인 NULL 포인터 + 구조체 오프셋 패턴입니다. 예를 들어((struct SomeStruct*)NULL)->field처럼, NULL인 포인터를 통해 구조체의 특정 필드에 접근하려다 발생한 것으로 보입니다.
당시에는 si_addr 값을 보면서도 이게 의미하는 바를 깊이 생각해보지 못했었다. NULL 포인터 역참조에 구조체 오프셋이 더해진 주소라는 것이고, Node.js 프로세스 내부의 어떤 네이티브 코드(dd-trace의 @datadog/pprof, V8 엔진 내부 등)에서 구조체 포인터가 NULL 상태로 접근이 시도된 것이다.
write(22)가 EAGAIN인 이유
당시에도 확인했지만 왜 EAGAIN이 발생하는지에 대한 설명은 하지 못했었다.
이 SIGSEGV 루프가 극도로 빠르게 돌면서 fd 22(파이프)에 16바이트씩 계속 쓰려고 합니다. 리눅스 파이프 버퍼는 기본 64KB인데, Consumer 쪽이 읽는 속도보다 SIGSEGV 루프가 쓰는 속도가 압도적으로 빠르니 순식간에 버퍼가 가득 찬 것입니다.
논리적으로 맞는 것 같다. SIGSEGV가 발생하고 핸들러가 복귀하고 다시 SIGSEGV가 발생하는 이 사이클은 거의 CPU 클럭 수준으로 빠르게 반복될 것이다. 어떤 Consumer가 파이프에서 읽어가더라도 이 속도를 따라잡을 수는 없다.
두 패턴의 관계
AI에게 “두 패턴이 관련이 있을 수 있을까?”라고 물었더니, 이런 시나리오를 제시했다.
- SIGPROF 폭격(CASE 1)으로 CPU가 과부하에 걸립니다.
- 과부하 상태에서 Node.js 프로세스 내부의 네이티브 코드(dd-trace, @datadog/pprof 등)에서 race condition이 발생하여 어떤 포인터가 NULL이 됩니다.
- 해당 포인터를 통한 메모리 접근 시 SIGSEGV가 발생합니다(CASE 2).
- SIGSEGV 무한 루프에 진입합니다.
즉, CASE 1이 CASE 2의 트리거였을 가능성이 있습니다.
이건 확인할 방법이 없지만, 논리적으로는 설득력이 있다. SIGPROF 폭격으로 인해 context switching이 과도하게 발생하면, 프로세스 내부 네이티브 모듈의 상태 관리가 꼬일 수 있다. 멀티스레드 환경에서 과부하 상태의 race condition은 NULL 포인터를 만들어내기 충분하다.
만약 그때로 돌아간다면
이 분석을 하면서, “그때 이런 것들을 해봤으면 더 명확한 답을 얻을 수 있었겠구나” 하는 것들이 보였다.
/proc에서 시그널 핸들러 확인
cat /proc/<PID>/status | grep Sig이 명령으로 어떤 시그널에 핸들러가 설치되어 있는지, 어떤 시그널이 마스킹되어 있는지 확인할 수 있다. Node.js 프로세스 내에서 SIGSEGV 핸들러가 설치되어 있는지, 그리고 어떤 컴포넌트가 설치한 것인지 확인하는 데 도움이 되었을 것이다.
메모리 매핑 확인
cat /proc/<PID>/mapssi_addr=0xe3a8 주소가 정말로 unmapped인지, 아니면 mapped이지만 권한이 없는 영역인지 확인할 수 있다. NULL 포인터 역참조가 맞는지 확인하는 가장 직접적인 방법이었을 것이다.
GDB로 faulting instruction 직접 확인
gdb -p <PID>GDB로 프로세스에 attach해서, SIGSEGV가 발생하는 정확한 명령어와 콜스택을 확인할 수 있었을 것이다. 어떤 코드가 NULL 포인터를 역참조하고 있는지 한 번에 알 수 있었을 것이다.
strace -k 옵션
strace -k -p <PID>-k 옵션을 사용하면 각 시스템 콜마다 커널 스택 트레이스를 함께 출력해준다. 시그널 핸들러의 호출 경로를 더 명확하게 볼 수 있었을 것이다.
틀린 분석으로 올린 PR, 그리고 리뷰어의 한마디
이번 재분석을 하면서 한 가지 더 한 일이 있다. CASE 2의 SIGSEGV 무한 루프 분석을 바탕으로, ddprof의 SIGSEGV 핸들러에 SA_RESETHAND 플래그를 추가하는 PR을 올렸다.
Add SA_RESETHAND to SIGSEGV handler to prevent infinite signal loop by yoochangyeon · Pull Request #487 · DataDog/ddprof
What does this PR do? Adds SA_RESETHAND flag to the SIGSEGV signal handler registration in src/ddprof.cc and test/simple_malloc.cc. With this flag, the kernel automatically resets the signal dispos...
SA_RESETHAND는 시그널 핸들러가 한 번 실행된 후 자동으로 기본 동작(SIG_DFL)으로 리셋되게 하는 플래그다. 이렇게 하면 핸들러가 실패하더라도 두 번째 SIGSEGV에서는 프로세스가 종료되니까, 무한 루프를 방지할 수 있다는 논리였다.
PR 설명에는 위에서 분석한 내용을 그대로 적었다. Node.js의 핸들러가 ddprof의 핸들러를 덮어써서 무한 루프가 발생한다는 시나리오를.
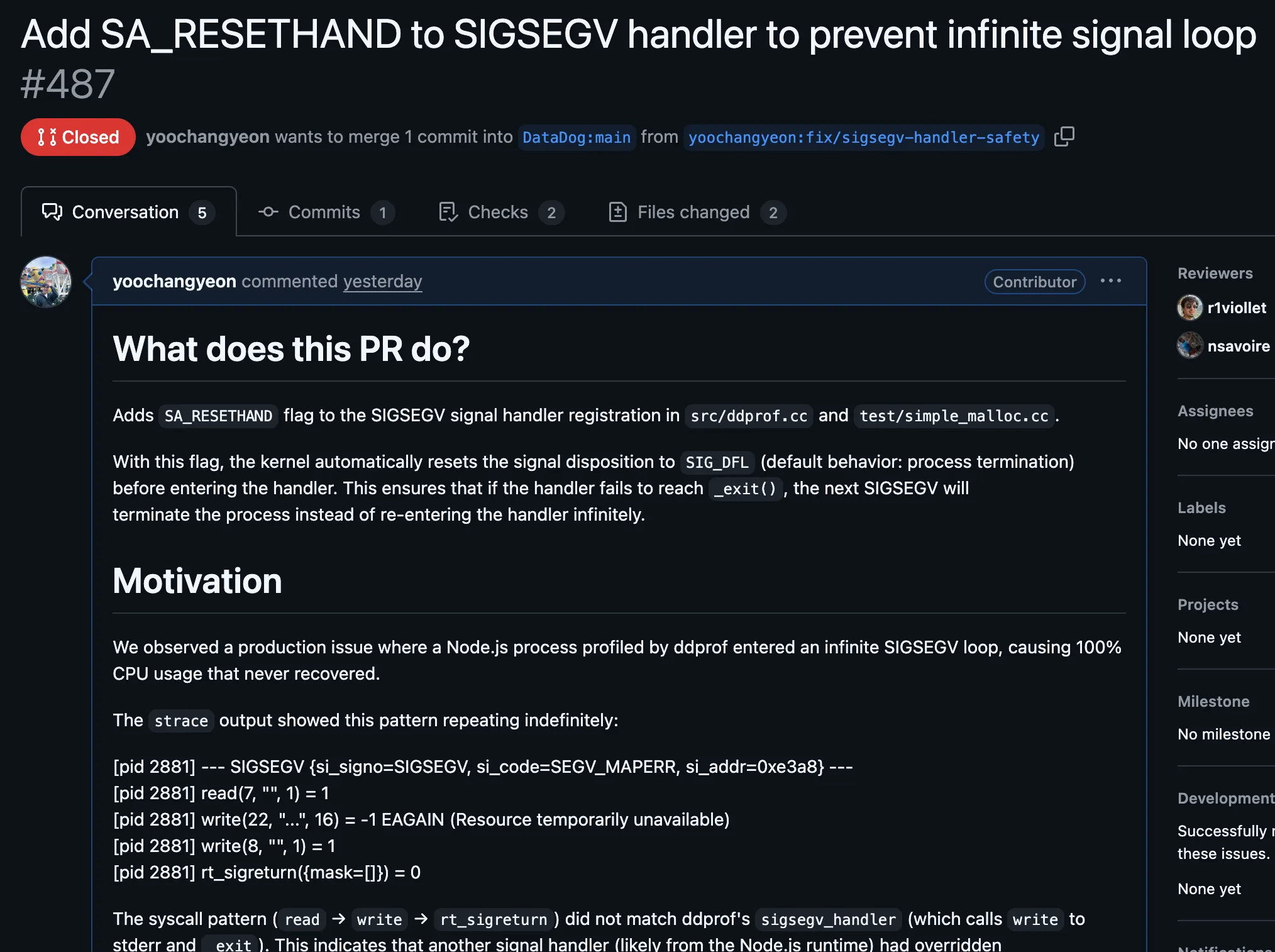
리뷰어(ddprof 메인테이너)의 답변은 이랬다.
Thanks for the contribution. I think that the change is fine.
코드는 좋다고 했다. 그런데 바로 다음 문장이 핵심이었다.
the handler is only installed in ddprof which runs in a separate process, so I have trouble understanding how Node’s handler could somehow interact with this handler.
ddprof는 별도 프로세스라서, Node.js의 핸들러와 상호작용할 수 없다는 것이다.
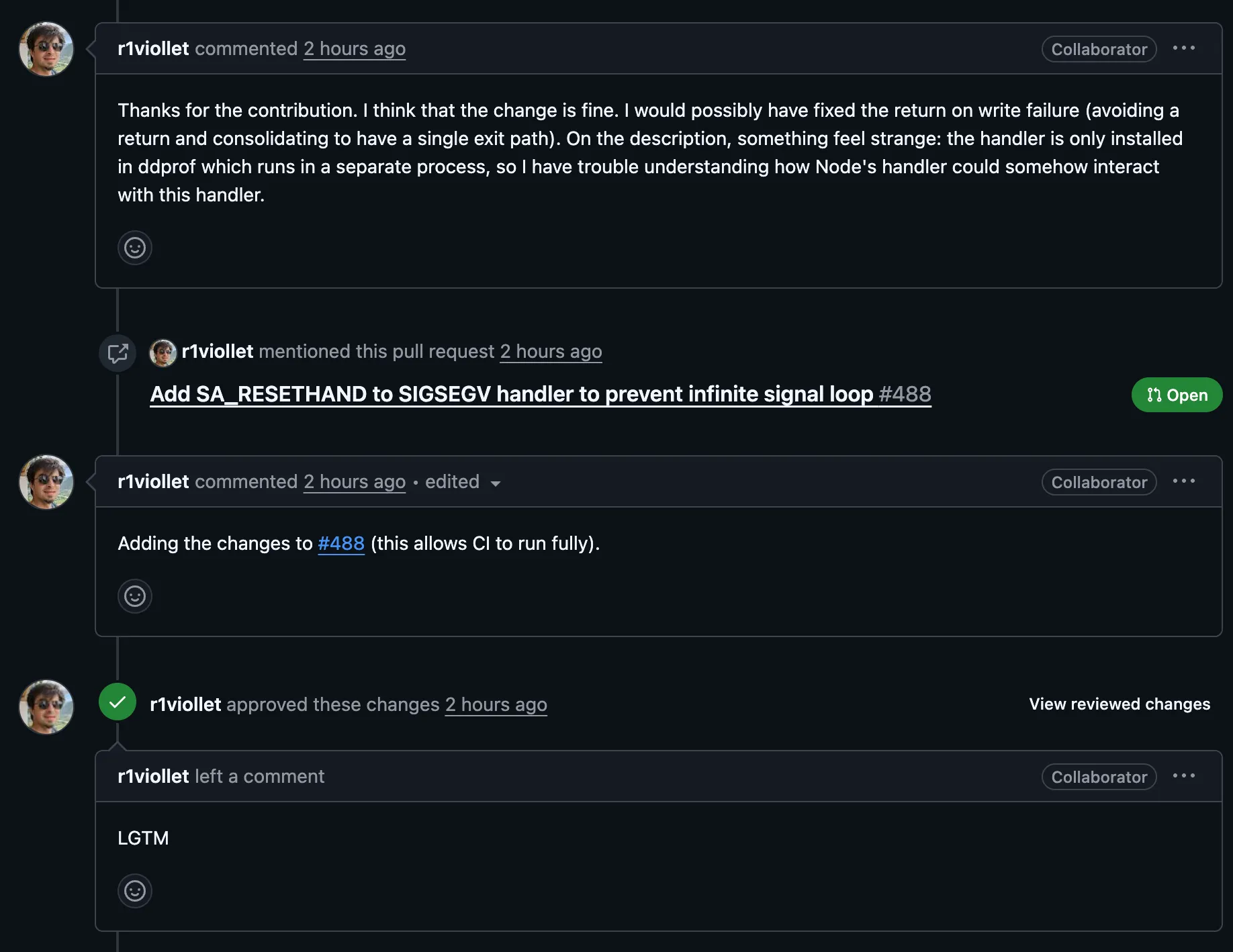
이 한 문장을 읽는 순간 머릿속이 하얘졌다. 그리고 바로 깨달았다. 내가 분석의 가장 기본적인 전제를 잘못 잡고 있었다는 것을.
결국 리뷰어는 PR을 #488에 머지해줬고, 마지막에 이렇게 덧붙였다.
however I doubt that this caused the issue you were observing.
맞는 말이다. SA_RESETHAND를 ddprof에 추가해봐야, Node.js 프로세스의 SIGSEGV 루프에는 아무 영향이 없다. 다른 프로세스의 코드를 바꾼 것이니까.
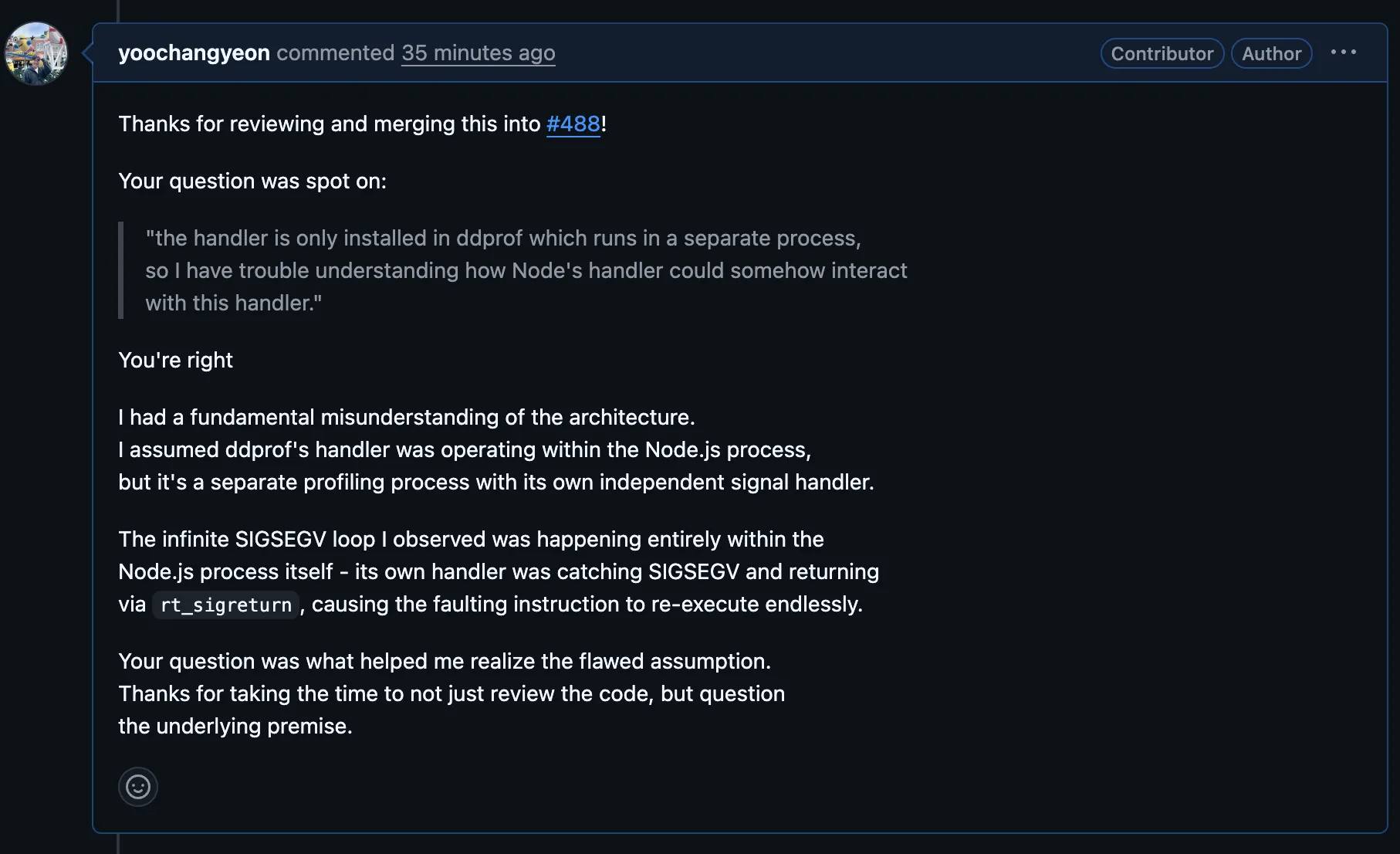
묘한 상황이다. 분석은 틀렸는데, 코드는 머지됐다. SA_RESETHAND 자체는 ddprof의 자체 크래시 핸들링을 더 안전하게 만드는 유효한 개선이었기 때문이다. 틀린 이유에서 출발했지만, 결과적으로는 도움이 되는 코드를 기여한 셈이다.
솔직히 부끄러웠다. 장문의 분석을 PR 설명에 적어놓고, 메인테이너한테 “그건 별도 프로세스인데요”라는 한 줄 피드백을 받은 것이니까. 하지만 이 경험이 결국 이 글의 CASE 2 분석을 수정하게 된 계기가 됐다. 틀린 걸 알아야 고칠 수 있으니까.
글을 마치며
정리하면, 이번에 다시 돌아보면서 알게 된 것과 여전히 모르는 것이 있다.
알게 된 것은, SIGSEGV 무한 루프의 메커니즘이다. 시그널 핸들러가 rt_sigreturn으로 복귀하면 faulting instruction을 다시 실행하게 되고, 원인이 해결되지 않았으니 영원히 반복된다는 것. 그리고 2편에서 ddprof 코드를 분석했던 것이 잘못된 방향이었다는 것. ddprof는 별도 프로세스라서, 그 안의 시그널 핸들러는 Node.js 프로세스와 아무 관련이 없었다.
여전히 모르는 것은, Node.js 프로세스 안에서 정확히 어떤 네이티브 코드가 NULL 포인터 역참조를 유발했는가이다.
1년 전에 근본 원인까지 파지 않고 업무를 마무리했던 판단은 지금도 틀리지 않았다고 생각한다. 해결 방법(프로파일링 끄기)은 이미 나와 있었고, 남은 것은 호기심의 영역이었으니까.
다만 그 호기심이 1년 뒤에 다시 이어졌고, AI의 도움으로 새로운 시각을 얻었고, PR의 리뷰어 덕분에 잘못된 전제를 바로잡을 수 있었다. 틀린 분석으로 PR을 올린 것은 부끄럽지만, 그 과정이 없었다면 ddprof가 별도 프로세스라는 사실도 모른 채 넘어갔을 것이다.
도구의 아키텍처를 먼저 이해하지 않고 코드를 분석하면, 그럴듯해 보이지만 틀린 결론에 도달할 수 있다. 이번에 제대로 배운 교훈이다.
결국 모르는 것을 알아가는 과정은, 1년이 지나도 끝나지 않는다.



