MySQL FULL TEXT INDEX 적용하기: ngram 파서로 한글 검색 최적화
LIKE 쿼리의 성능 한계를 극복하고 한글 닉네임 검색 속도를 개선한 FULL TEXT INDEX 적용 경험과 제로 다운타임 배포 전략을 공유합니다.

문제 상황: 느린 닉네임 검색
최근 프로젝트에서 특정 글자를 포함한 닉네임을 가진 유저를 검색하는 데 시간이 오래 걸린다는 이슈가 있었다. ‘푸릉’을 검색하면 ‘김푸릉’, ‘푸릉이’ 등 ‘푸릉’이라는 단어를 포함한 닉네임의 유저를 찾아야 하는데, 검색 속도가 너무 느렸다.
코드를 살펴보니 Prisma에서 contains를 사용하여 검색하고 있었고, 데이터베이스로 전달되는 실제 쿼리는 LIKE '%푸릉%' 형태였다.
원인 분석: LIKE 쿼리와 인덱스의 한계
먼저 확인한 것은 이 쿼리가 인덱스를 사용하고 있는가였다.
닉네임 컬럼에 인덱스가 있음에도 불구하고, 인덱스를 사용하지 않고 있었다.
왜 인덱스를 사용하지 못했을까?
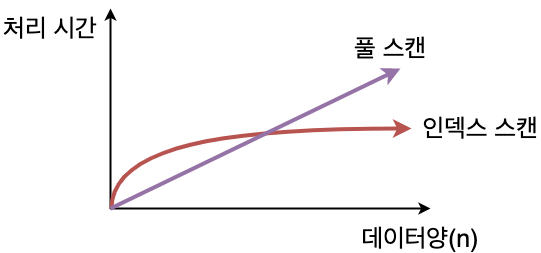
문제의 원인은 LIKE 쿼리가 인덱스 사용에 제한이 있다는 것이었다. MySQL InnoDB에서 인덱스는 B+ 트리를 사용하기 때문에, 닉네임이 B+ 트리로 구성되어 있을 때 LIKE '%닉네임%' 쿼리는 트리를 통한 검색이 불가능하다.
이는 와일드카드 %가 문자열의 앞에 위치하면 인덱스를 활용할 수 없기 때문이다.
-- 인덱스 사용 가능 (앞부분 일치)
SELECT * FROM users WHERE nickname LIKE '푸릉%';
-- 인덱스 사용 불가능 (중간 포함)
SELECT * FROM users WHERE nickname LIKE '%푸릉%';이를 해결하기 위해 FULL TEXT INDEX를 적용해보기로 했다.
FULL TEXT INDEX란?
FULL TEXT INDEX는 MySQL에서 제공하는 전문 검색(Full-Text Search)을 위한 인덱스이다.
일반적인 인덱스가 문자열의 시작부터 매칭되는 경우에만 효율적인 반면, FULL TEXT INDEX는 문자열의 중간이나 끝부분에 있는 단어도 효과적으로 검색할 수 있다.
FULL TEXT INDEX 생성하기
첫 번째 시도: 기본 FULL TEXT INDEX
바로 nickname에 대해서 FULLTEXT INDEX를 만들어서 적용해주었다.
ALTER TABLE users
ADD FULLTEXT INDEX idx_nickname (nickname);‘푸릉’을 검색했는데, 아무것도 나오지 않았다.
속도 개선이 안되면 어떡하나 걱정하고 있었는데, 아예 검색이 안되는 것은 상상도 못했다.
문제 원인: 한글 처리 불가
문제를 확인해보니 기본적으로 MySQL의 FULLTEXT INDEX는 영어와 같이 공백으로 단어를 구분하는 언어에 최적화되어 있다.
한국어와 같이 공백으로 단어를 구분하지 않는 언어를 처리하기 위해서는 ngram 파서를 사용해야 한다는 것을 알게 됐다.
ngram 파서 적용
수정된 인덱스 생성
ALTER TABLE users
ADD FULLTEXT INDEX idx_nickname (nickname)
WITH PARSER ngram;ngram parser를 이용한 인덱스를 새로 생성해주었다.
MATCH AGAINST 쿼리 사용
또 FULLTEXT INDEX가 걸려있는 컬럼에서 인덱스를 활용하기 위해서는 검색 쿼리도 LIKE 쿼리가 아닌 MATCH 쿼리를 사용해야 한다.
SELECT * FROM users
WHERE MATCH(nickname) AGAINST('푸릉' IN BOOLEAN MODE);이제 ‘푸릉’을 검색하면 ‘김푸릉’과 ‘푸릉이’를 모두 검색할 수 있게 됐다.
성능 개선 결과
인덱스도 사용하게 됐고, 실제로 속도가 매우 빠르게 개선되었다.
-- LIKE 쿼리 실행 계획 (개선 전)
-> Table scan on users (cost=0.00..500.00 rows=10000)
Filter: (users.nickname like '%푸릉%') (cost=0.00..500.00 rows=100)
Rows examined: 10000
Rows returned: 100
-- MATCH AGAINST 실행 계획 (개선 후)
-> Full-text index lookup on users using idx_nickname (cost=0.50..5.50 rows=100)
Rows examined: 100
Rows returned: 100한글자 검색이 안된다
이제 ‘푸’만 검색해도 ‘푸릉이’가 나와야 한다.
문제가 생겼다. ‘푸릉’을 검색하면 ‘푸릉이’가 나오는데, ‘푸’를 검색하면 ‘푸릉이’가 안나온다.
ngram 토큰 크기 문제
확인해보니 ngram parser는 기본적으로 두 글자로 묶어서 인덱스를 만든다고 한다.
예를 들어 ‘김푸릉이’라는 닉네임이 있다면, ‘김푸’, ‘푸릉’, ‘릉이’ 이렇게 두 글자씩 인덱스를 생성해두기 때문에 ‘푸’를 검색하면 어느 것도 검색되지 않았다.
ngram_token_size를 변경하자
MySQL의 ngram_token_size 값을 1로 수정해주면 된다고 했다.
문제점들
- DB 재시작 필요: 이를 위해서는 DB를 재시작해야 한다는 것이다.
- 동적 변경 불가: RDS 파라미터에서도 확인해봤더니 dynamic으로 설정할 수 있는 파라미터가 아니어서 재부팅 후 적용되도록 되어있었다.
- 인덱스 크기 증가:
ngram_token_size를 1로 줄이게 되면 인덱스 크기가 훨씬 커진다는 단점이 있었다.
온라인 DDL의 한계
온라인 DDL을 사용해서 최대한 빠르게 index를 생성할 수 있지만, WRITE, UPDATE 쿼리에 락(LOCK)이 발생하는 것은 막을 수가 없었다.
READ에는 락이 걸리지 않기 때문에 UPDATE나 WRITE 작업이 자주 일어나지 않는 테이블이라면 큰 문제 없이 생성할 수 있을 것 같다.
다만 내가 하고 있는 프로젝트에는 위험을 굳이 감수하지 않고 다른 방향으로 문제를 해결하게 되었다.
FULL TEXT INDEX 생성에 제로 다운타임이 가능한가?
만약 인덱스를 실제로 생성해야 했다면 나는 이렇게 진행했을 것 같다.
Blue-Green 배포 전략
- RDS Blue-Green 배포 생성
- Green DB에서 FULL TEXT INDEX 생성: Green DB이기 때문에 인덱스 생성 시간이 아무리 길어져도 상관 없다는 장점이 있다.
- Blue-Green 교체: 30초 이내의 다운타임이 발생하게 된다.
결국에는 다운타임이 발생한다
Blue-Green 전환은 심지어 READ 쿼리도 동작하지 않게 된다. 그럼에도 이 방식을 선택하는 이유는 통제권을 최대한 갖고 있기 위해서이다.
만약 실제 상용 DB에서 CREATE INDEX를 실행했는데, 쿼리가 예상보다 오래 걸려서 패닉에 빠지거나, 인터넷이 끊기거나 등등 여러 가지 변수가 생기면 CREATE INDEX 쿼리를 취소하는 판단을 하거나 기다리는 판단을 하게 된다.
이 여러 변수를 허용하지 않고 최대한 통제하기 위해서 RDS에게 위임을 해버리는 것이다. 이런 것을 위해 RDS를 비싼 돈을 주고 사용하고 있다..^^
만약, Zero Down Time을 고수해야 한다면
누군가 나에게 큰 비용을 사용해도 괜찮으니 다운타임이 없어야 한다 라고 한다면 이렇게 시도해볼 것 같다.
테이블 복제 전략
user_2(가칭) 테이블 생성- 트리거 작성:
user테이블에서 row의 변경사항이 생길 때마다user_2테이블로 전파되도록 트리거 작성 user_2테이블에 FULL TEXT INDEX 작성- 코드 배포: 코드상에서
user테이블을 보고 있는 코드를user_2테이블을 바라보도록 수정해서 배포
-- user_2 테이블 생성
CREATE TABLE user_2 LIKE user;
-- 기존 데이터 복사
INSERT INTO user_2 SELECT * FROM user;
-- 트리거 생성 (INSERT)
CREATE TRIGGER sync_user_insert
AFTER INSERT ON user
FOR EACH ROW
INSERT INTO user_2 VALUES (NEW.*);
-- 트리거 생성 (UPDATE)
CREATE TRIGGER sync_user_update
AFTER UPDATE ON user
FOR EACH ROW
REPLACE INTO user_2 VALUES (NEW.*);
-- 트리거 생성 (DELETE)
CREATE TRIGGER sync_user_delete
AFTER DELETE ON user
FOR EACH ROW
DELETE FROM user_2 WHERE id = OLD.id;
-- FULL TEXT INDEX 생성
ALTER TABLE user_2
ADD FULLTEXT INDEX idx_nickname (nickname)
WITH PARSER ngram;이런 방식을 사용한다면, zero down time으로 full text index를 생성할 수 있을 것 같다.
마치며
LIKE '%검색어%'가 인덱스를 못 타는 문제를 FULL TEXT INDEX + ngram 파서로 해결할 수 있었다. 다만 ngram_token_size 변경에 DB 재시작이 필요하다는 점, 인덱스 크기가 커진다는 점은 트레이드오프로 남는다.
인덱스 생성 자체도 운영 중인 DB에서는 신경 쓸 부분이 많았다. 결국 Blue-Green 배포로 통제권을 확보하는 방향을 택했는데, 제로 다운타임이 반드시 필요하다면 테이블 복제 + 트리거 방식도 고려해볼 만하다.
![[MySQL] MySQL에서의 CRUD (Create, Read, Update, Delete)](/_astro/image-0.BxA8kSPI.png)