인덱스(Index)란? (Index의 종류와 특징)
· 유창연 · 3 min read
데이터베이스 인덱스의 개념과 클러스터드/넌클러스터드 인덱스의 차이, B-Tree 구조, 중복도 고려사항을 정리합니다.
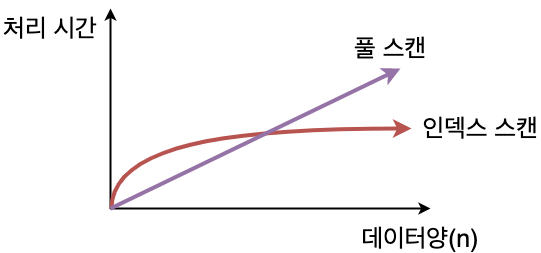
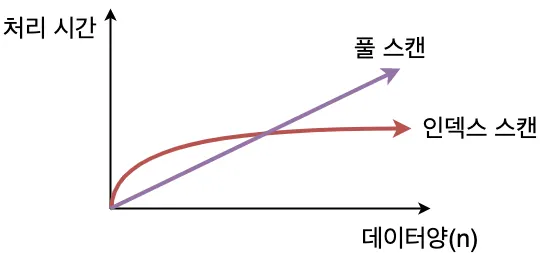
- 종류
- 클러스터드 인덱스(Clustered Index)
- 하나의 테이블에 한 개만 생성 가능하다.
- 순서대로 정렬된다. 자동 정렬된다.
- 범위 검색에서 강력하다.
- 순서대로 정렬되는 특징 때문에 insert가 어렵다.
- 넌 클러스터드 인덱스 (Non Clustered Index)
- 하나의 테이블에 여러개를 생성할 수 있다.
- 특징
- 검색 속도 향상 : 인덱스를 사용하지 않을 때는 full scan을 하기 때문에 속도가 느리다.
- 추가 공간이 필요하다 : 공간의 약 10%정도를 차지한다고 알려져 있다.
- insert시 추가 작업 필요 : index과정이 필요하기 때문에 insert시에 작업이 추가된다.
- 중복도
- Index를 사용하는 가장 큰 이유는 값을 빠르게 찾기 위해서이다.
- 때문에 Index를 사용할 때는 테이블에 들어오는 값들의 중복도를 고려해야한다.
- ‘성별’ 컬럼에 Index를 적용시키면 ‘남’, ‘여’로만 구분되어서 값의 중복도가 크다. Index의 의미를 잃을 수 있다.
- 즉 값의 중복도가 작은 컬럼들을 위주로 Index를 적용해주면 좋다.
- B-Tree
- MySQL에서 대부분의 인덱스 (Primary Key, Unique Key, Index)는 B-Tree 자료구조를 사용한다. (FullText Index는 B-Tree가 아닌 Inverted Index(역색인)를 사용한다.)
- 메모리 테이블은 hash Index가 사용된다.
- Binary Search Tree와 유사하지만, 한 노드당 자식 노드를 2개 이상 둘 수 있다는 차이가 있다.
- 어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다는 ‘균일성’이 장점이다.
- https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Tree

![[MySQL] MySQL에서의 CRUD (Create, Read, Update, Delete)](/_astro/image-0.BxA8kSPI.png)
